
Adding Comment Support
As you may know, I added comments support! This is by no means a revolutionary thing for a website. But I thought it gave me a good excuse to talk a little bit of tech so I can justify the .dev extension.
This site is freely hosted on Vercel. This means I want to lean into whatever the optimal platform solution is; I'm not making something novel here, just a custom blog and personal website. I haven't used Vercel before this site - and I'm actually quite impressed with it.
In addition to the technical requirements above, I had a list of requirements for myself to keep the project simple and safe:
Comment access needs to be whitelisted.
I don't want to spend my days being a comment moderator for bots. I didn't just want to need to approve comments, I wanted it to not even be possible unless you were someone I knew, or someone to whom I granted access.
I store an absolute minimum amount of data per user
Not that I expect my tiny little site ever to get hacked or have a data breach, but if it did, I wanted nothing personal to be leaked. It limits what is available to the site when the user is not actively using it, but that's OK!
I pick a database reasonably suited to the task of reading sorted, partitioned data; and, one that was supported by Vercel
I host a rack at home with a few servers, and originally I had intended to use it to host my website. But I wanted to try something new and use Vercel because I've heard good things about it, and my blog is written using Next.js anyway.
Picking a Database
The first choice I needed to make was to pick a database. This database was going to be used for any auth-level data which required storage, as well as possibly the comment data too. Ordinarily I might choose two separate databases, but to stay within the Vercel free tier I would need to use a single one.
Vercel supports a few different types of databases
Between all of the above options, we are really left with only two that are viable. While Edge Config and Blob systems can be very useful, not so much for comments storage.
So then the choice is between Postgres and KV.
For authentication tokens, KV is great. I know I need to handle the auth cases in addition to the comments, so that was one token in favor of KV. Having the ability to use ttls for keys helps with session durations or token expiration.
The thing I was unsure about is the persistence story. Redis is generally not used for persistence because it is optimized for quick in-memory transactions - not for writing to durable storage. However, KV is advertised as durable Redis, not vanilla Redis, so I was intrigued by this.
Postgres was clearly the safe option. It can do everything you would want a database to do. I'd also get the benefit of being able to do joins on data sets which would be nice. But it is way more heavy handed and robust, and probably more than I'd need.
With these two options considered, I chose KV. The biggest reason for the choice was to experiment with some of the more niche Redis operations, and because with the levels of storage I should need - provided the comments are durably stored - Redis will provide faster access.
Designing the Auth System
With the database selected it was time to figure out how I wanted to do the authentication. I wanted, first and foremost, to store as little data as possible. I didn't want to deal with storing passwords or real names, and then needing to deal with password resets and the like.
My first inclination was to add support to log in with Google. While this was enticing, and would allow me to use some off the shelf libraries, it meant users would need to have a Google account. I didn't want to then need to support multiple login methods (which is what most sites do to get around this problem) because it is unneeded complexity; I am not providing a service - I just need to authenticate in order to authorize the comments.
So then I though about using Auth0. This would allow me to integrate once and support whatever else I wanted, but having a full OAuth flow seemed overkill for what I needed.
I decided to go the simplest possible approach, and to do so I took some inspiration from a service called Shop.
When you check out on a website and enter in your email address, Shop looks up your account information and sends you an email to verify you are actually the person shopping. After you approve it, you're given a token that can be used to make a Shop transaction. You never need to create an account or enter a password - it uses your email (or phone number) to authenticate you.
With that, I came up with a simple flow that follows a similar pattern:
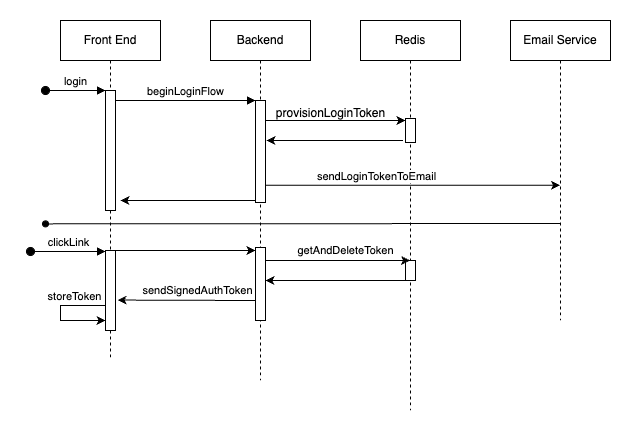
beginLoginFlow
The user initiates a login flow, providing the email address they entered into the form. This is sent to the server to begin the login request.
provisionLoginToken
The server hashes the user's email to locate the Redis key the user's authorization information is in. It then generates a cryptographically random string to use as the token ID. Using the token ID and the authorization information, the server signs a JWT and stores it in Redis with a short expiration time.
sendLoginTokenToEmail
After creating the login token and its ID, the server sends an email with login link which contains the token ID. The token ID itself is a hard string to brute force, and since it lasts only a short time it makes it unlikely to be guessed. This is the link that you'll click when you push the login button in the email.
clickLink
The user requesting to log in clicks the link in the email. This directs them to a page, providing only the login token ID and their hashed email address.
getAndDeleteToken
The server uses a redis getdel operation to read the login token at the position of its ID. If the token is expired, nothing will be found and the login will fail. If the token is not expired, it will be fetched and deleted, denying repeated attempts at using the link.
sendSignedAuthToken
The signed authentication token is now sent back to the front end so it can be stored and used.
storeToken
The front end saves the login token to local storage where it can be provided to requests that need to be authenticated. When this token is provided to the server, the server uses the signing secret to verify the signature of the contents, and uses this to authenticate and authorize the logged in user to certain actions.
The login token, which is not stored on the servers except for the short ttl, contains:
- The user's display name
- The user's email address
- The user's level of access
- The ID of the key used to sign the token (monotonically increasing for key rotations)
The servers user data only provides the access flags and the display name. The email address is never stored anywhere on the servers except during the transaction with a short time-to-live. The hash of the email is used to lookup the above two pieces of user data. This means the email is only ever stored temporarily.
Now that the user is logged in, they can comment! If they've been given access... Otherwise, the site informs the user that they need to request comment access.
Comments
Schema
The comment schema is pretty simple, and just looks like this:
{
"userId": "", // hashed email address of the user making the comment,
"commentText": "", // text from the comment. HTML entities are encoded.
"slug": "" // the post URL the comment was left on
}
You'll note I don't have any of the display names in the comment schema. This is to allow them to change and have that change reflected in any of the comments made on the site. Knowing the user ID allows us to look up the display name of the author.
Storage
To store this data I use a Redis sorted set. Sorted sets allow data to be stored in a series ordered by a score. In this case I use the timestamp of the comment, in UTC time, to score and sort the posts.
Fetching from a sorted set allows us to easily paginate. I haven't added pagination support yet - because I figure the number of comments will be pretty low - but it will be easy to add later.
After we fetch a chunk of posts, I create a Set object in Javascript of all the user IDs in a set of comments. I then can do a mget operation to read the set of keys in bulk to populate their display names. Afterward, I transform the comments and enrich them with the user's display name.
Possible Improvements
If you're looking to add a comments system to your application and are taking any inspiration from me, here are some improvements you could make to the system that I decided not to do (at least, yet).
Salted user IDs
Using a salt with hashes means it will be harder to do a rainbow table attack. This is totally unnecessary for my site but just keep this in mind for yours. This is nearly mandatory for password safety.
Replies Support
Adding support for threads, or replies, will be very difficult using the Redis sorted set architecture. Since the current score which sorts the keys is just the timestamp, replies would get sorted later and not be loaded in order next to the original post.
There are a few ways you could do this depending on the level of nesting you wanted to support:
- Make the score compound for replies.
By having a reply's score be the parent posts's score, plus the reply's timestamp in decimal notation, you would ensure the sort order is correct. The fractional part of the number will make it larger than the original timestamp, causing it to be sorted later. However, subsequent replies to the post will have a larger timestamp and thus be sorted after the reply.
This will only work for one level of nesting, however
- Store replies in their own key in Redis
If the comment keyspace is comments/post_id, replies to a given comment could be stored in comments/post_id/comment_id. Nested replies could work similarly, as they would have their own comment IDs.
This will allow for unlimited amounts of nesting, but it has a significant drawback: multiple queries to redis are required to populate a comment section. Additionally, if you don't mutate the original record to signal that there are child comments (or the number thereof), you'll need to optimistically load replies for all comments even though most may not have them.
Since I am using a sorted set, I cannot update records. This means I can't mutate or increment a value inside the original comment data.
Instead, we can use the KEYS command with a pattern to load child comments. This means to load comments we can do this:
MULTI
ZRANGE 'comments/post_id' 0 100
KEYS 'comments/post_id/*'
EXEC
This will get the first 100 comments, and will get entire set of comments that have child comments.
Since we only know the comments that have child comments, and not the content of their child comments, we would need to load the actual content afterward. I think the best way to do this from a UI perspective is either to load 1 level of nesting always for the comments we read, or to have a button that says "View Replies" that a user can push. Since we know if there are replies to a comment we can render it conditionally.
Pagination Support
As mentioned, I am using a sorted set to store the comments. While pagination would be easy to add, it isn't currently. I made this choice because I figured the number of comments on my little site would be pretty low, but if you were using this architecture for a larger site it would definitely be insufficient.
To add comments you'd simply need to provide the indices to the ZRANGE command when loading the comments. As long as you sort earliest comment to latest comment, you can assume no new earlier records will sneak in. If you sort the opposite way it is actually possible to miss records or get redundant records based on user activity in the background, so keep that in mind.
If you do it that way you'll want to paginate not by index, but BYSCORE. This will allow you to provide the last loaded timestamp (which is the score) and get only the records after that one. You can then also provide a LIMIT to limit the number of records returned.
Cold Storage
Using Redis for all of the comments may be difficult if your site gets a lot of comments. Redis can really only scale to the limits of its memory unless you use storage on-disk, which makes it much slower.
If you want to be able to handle a huge number of comments on the site and more complex searching within those comments, I'd highly recommend using a different database (like Postgres). Redis can still be tremendously useful for the "hot storage" to make sure comments are served fast, acting as a read-through cache.
Conclusion
I hope you enjoyed this little insight into this technical project. I will do some posts on more serious technical topics at some point as well, I'm sure!